고정 헤더 영역
상세 컨텐츠
본문
'동기화'문제로 고민한 썰
동기화 문제
이펙티브 자바를 읽던 중, 아이템 78에 있는 자바 동기화 문제로 다양한 상상(?)을 했던 썰을 풀려고 합니다.
import java.util.concurrent.TimeUnit;
public class Main {
private static boolean stopRequested;
public static void main(String[] args) throws InterruptedException{
System.out.println("hello world!");
Thread backgroundThread = new Thread(() -> {
int i=0;
while(!stopRequested){
i++;
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}다짜고짜 코드부터 나와서 당황할 수 있지만, 위 코드는 동기화 문제로 종료되지 않는 코드입니다.
왜 이 코드가 동기화 처리를 하지 않았기 때문에 종료되지 않는지 단 번에 맞추실 수 있는 사람은 뒤로 가기를 누르는 게 좋습니다.
저는 이 코드가 왜 동기화 문제인지에 대해서 이해하지 못했습니다.
심지어 동기화 문제로 적절한 예시가 맞는지에 대한 의심도 했습니다.
왜냐하면 자바 동기화라 함은 멀티 스레드 환경에서 공유되는 변수에 동시에 접근하려고 할 때 즉, 스레드끼리 경쟁하는 상황에서, 공유되는 데이터의 정합성(?)이 맞지 않는 문제를 처리하는 방법으로 알고 있었기 때문입니다. (동기화를 아예 모르는 상태는 아니었습니다...)
그래서 스레드를 여러 개 만들고 공유되는 Integer값에 1씩 더하면서 총합(SUM)을 계산하는 그런 예시가 더 적절하지 않나 생각했습니다.
그런 생각을 하던 상태이기 때문에 위의 코드가 왜 멈추지 않는지 이해를 못했습니다.
그 이유가 동기화 처리를 하지 않았다는 이유로 말입니다.
main thread가 stopRequested의 값을 true 로 만들 때, backgroundThread 가 설령 동기화 처리를 안 한 변수(stopRequested)에 먼저 접근해서 false 값을 가져오더라도 다음 반복문에서 true 로 바뀐 것을 알아챌 수 있다고 생각했습니다.
결국에는 아래처럼 코드를 돌려보고 고민이 시작되었습니다.
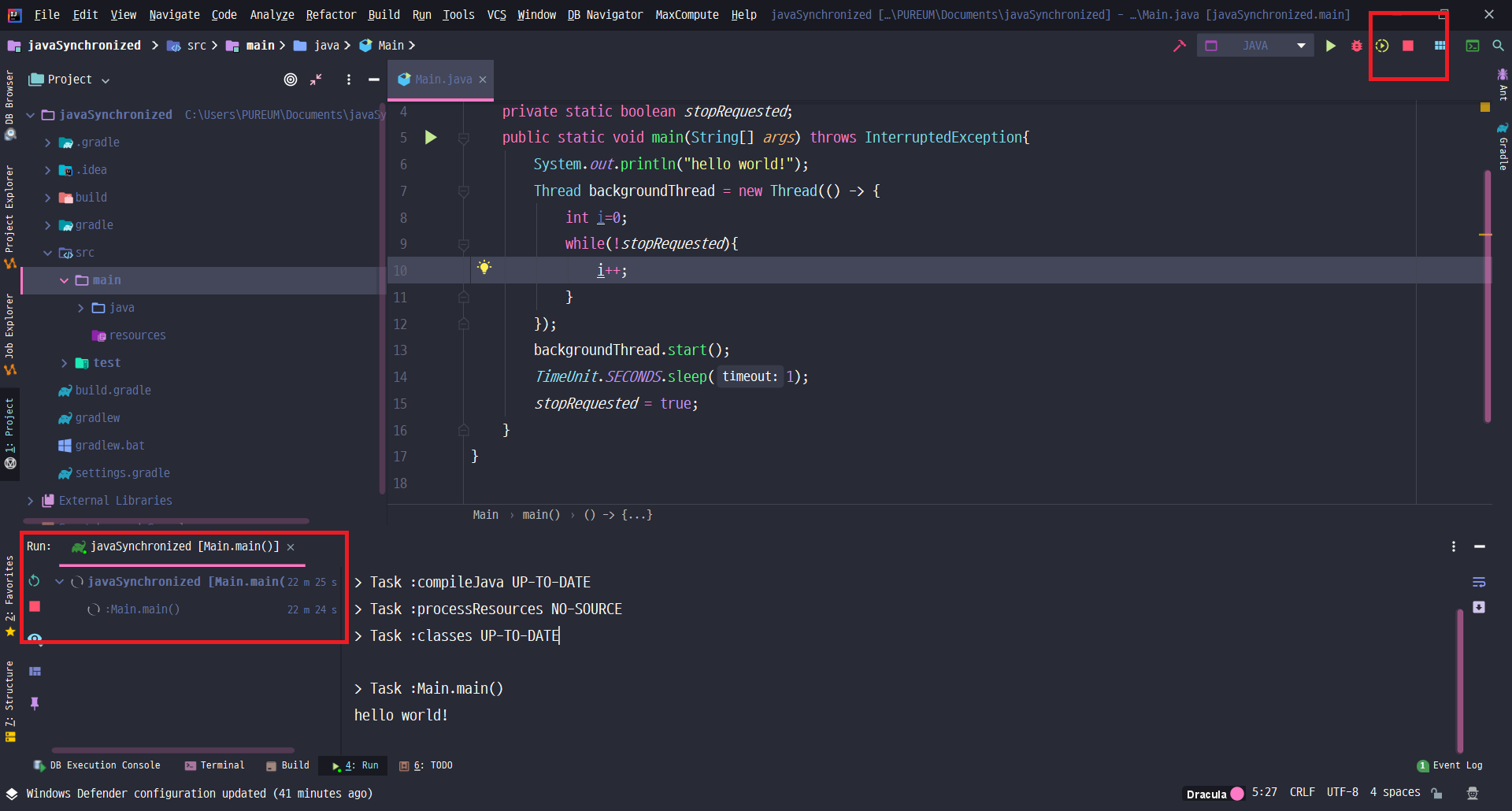
실제로 끝나지 않는 모습을 확인할 수 있습니다. 왼쪽 하단에 22분이 넘도록 돌고 있고, 오른쪽 상단에 중지 버튼이 활성화되어 있는 것을 확인할 수 있습니다.
콘솔을 찍어보자
정말로 안 끝나고 있는 게 맞는지 콘솔을 찍어봤습니다.
public class Main {
private static boolean stopRequested;
public static void main(String[] args) throws InterruptedException{
System.out.println("hello world!");
Thread backgroundThread = new Thread(() -> {
int i=0;
while(!stopRequested){
i++;
}
System.out.println("exit loop");
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
System.out.println("main end");
}
}main thread 가 정상적으로 끝나는지도 찍어보고, backgroundThread 가 반복문을 빠져나오는지도 찍어봤습니다.
역시나 backgroundThead 가 종료되지 않고 계속 실행되었습니다.
다음으로 반복문 내부에서도 계속 실행되는지 콘솔을 찍어봤습니다.
그런데 이제는 어느정도 수행하다가 종료가 되었습니다. 왜?
System.out.println() 하나 추가되었다고 몇 번 찍다가 변숫값의 변경을 알아채는 게 아주 의아했습니다.
이제는 멘탈이 깨져서 System.out.println() 에 무슨 문제가 있나? 하기도 했습니다.
항상 똑같은 시기에 스레드(backgoundThread)가 종료되지도 않고 왔다 갔다 하니까 더 헷갈렸습니다.
정답
여러 고민과 테스트 코드를 작성하던 중 책을 조금 더 읽다가 알아냈습니다. 정답은 캐시에 있었습니다.
CPU에는 L1, L2, L3 캐시가 존재합니다. '최근에 쓰인 데이터는 금방 다시 쓰일 확률이 높다'라는 이론(?)을 바탕으로 데이터를 캐시 하는 곳입니다. (캐시 전략은 다양하게 존재할 수 있습니다.)
바로 이 곳에 캐시된 공유 변수(stopRequested)를 동기화해주지 않았기 때문에, 다른 스레드에서 실질적으로 메모리에 값을 true로 변경하였더라도, 반복문에 쓰이고 있는 CPU의 스레드에서는 L1, L2와 같은 곳에 캐시 된 값을 참고하고 있어서 동기화 문제였던 것이었습니다.
충격적인 것이, 스프링 공부를 하면서도 @Cacheable 로 캐시 하고 데이터가 변경되면 @CacheEvict 로 캐시를 제거해줘야지! 즉, 데이터 동기화를 해야지 이런 내용들을 알고 있었음에도 위 문제에서 동기화를 생각해내지 못했던 것입니다.
AtomicInteger 니, ConcurrentHashMap 이런 것도 다 알고 있었으나 이런 부분에서 동기화를 이해하지 못한 것에 대한 아쉬움이 남습니다...
책에서도 정확하게는 그렇게 쓰여있습니다. backgoundThread 가 언제 종료될지 예측할 수 없다고.
즉, 캐시가 언제 비워져서 변경된 값을 언제 참조할지를 모르는 것입니다.
System.out.println() 메소드를 호출할 때는 왜 캐시가 비워지는지 모르겠습니다.
뭘 호출하느냐에 따라 다른가? 하고 System.out.println(stopRequested) 도 해봤는데요, 느낌상(?) 이미 캐시 된 stopRequested 의 경우에 계속 호출하더라도 캐시가 지워지지 않아야 하지 않나? 했는데 중간에 변경된 값을 참조하더라고요. i값, 고정된 문자열(ex. static final String = "hello")을 찍어도 캐시가 지워지지 않아야 하지 않나? 했는데 말이죠.
그냥 빈 System.out.println 만 해도 스레드가 종료되는 것으로 보아 메서드 프린트 메서드만해도 뭔가 캐시에 새로운 게 쌓이는 구나하고 말았습니다... (정확한 정보는 알려주실 수 있는 분이 댓글로 남겨주시면 아주 감사하겠습니다.)
volatile
volatile 키워드가 자바에 있습니다.
이 키워드를 적용한 변수는 L1, L2등에 캐시를 참고하지 않고 직접 메모리를 참조하도록합니다.
private static volatile boolean stopRequested;따라서 위 코드처럼 변수에 volatile 키워드를 적용하면, 캐시 때문에 동기화가 이뤄지지 않는 문제는 얼추 해결되는 듯 보입니다.
하지만 완전히 동기화 문제가 해결되는 것은 아닙니다.
메모리를 직접 참고하더라도 스레드 간의 접근에 의한(?) 동기화 문제는 남아있기 때문입니다.
이럴 때는 락(lock)을 이용한 동기화 처리를 해줘야 합니다.
synchronized 키워드가 여기서 사용되는 것입니다.
Synchronized 주의 사항
synchronized 키워드에 대해서 설명하는 포스트는 아니기 때문에 이번에 새로 알게 된 주의할 점만 간단하게 설명하도록 하겠습니다.
서비스 애플리케이션을 개발할 때는 주로 DB, NoSQL등에 의존한? 동기화 처리를 사용하고, 굳이 사용하는 경우가 있더라도 ConcurrentHashMap이나 AtomicInteger와 같이 자바에서 제공하는 안전한 변수를 이용할 텐데요.
혹시라도 synchronized를 사용한다면 다음을 주의해야 합니다.
public class MyAtomicInteger {
private int value = 0;
public void plus(){
synchronized (this) {
value++;
}
}
public int get(){
synchronized (this) {
return value;
}
}
//... 많은 메소드들이 있다고 가정...
public int plus2() {
return value++;
}
}임의로 만든 클래스(MyAtomicInteger)입니다.
synchronized를 열심히 작성하여 동기화된 메소드 들을 만들어서 Thread safe 하게 해 놨다고 칩시다.
그러면 value 에 대해서 항상 Thread safe라고 말할 수 있을까요?
아닙니다. 만약 다른 동료가 개발할 때 해당 변수에 대해서 동기화 처리하지 않으면 MyAtomicInteger 클래스의 변수 value에 대해서 동기화를 보장하지 않게 됩니다.
위의 예시에서는 plus2()와 같은 메소드를 만들면 동기화가 깨집니다.
굳이 value를 수정하는 것이 아니라 get과 같이 변수를 변경하지 않더라도 synchronized 처리를 하지 않으면 동기화가 깨집니다. 위에서 한참 설명한 캐시와 같은 경우에 말이죠.
따라서 synchronized 키워드를 사용할 때는 같이 개발하는 모든 개발자가 알 수 있도록 해야 하고 항상 관리되어야 하는 위험이 있습니다.
그것을 주의하여 코딩해야 하는 것을 이번 기회에 배웠습니다.
좋아요18
공유하기
게시글 관리
공유 중인 가변 데이터는 동기화해 사용하라#
item 78
- synchronized 키워드는 메서드나 블록을 한 번에 한 쓰레드씩 수행하는 것을 보장한다.
- 동기화의 중요한 기능 중 하나는, 동기화 없이는 한 스레드가 만든 변화를 다른 스레드에서 확인하지 못할 수 있다는 것이다.
- 동기화는 일관성이 깨진 상태를 볼 수 없게 하는 것은 물론, 동기화된 메서드나 블록에 들어간 스레드가 같은 락의 보호하에 수행된 모든 이전 수정의 최종 결과를 보게 해준다.
- 그래서 스레드가 저장한 값이 다른 스레드에게 보이는 것도 동기화가 있기에 가능하다.
- 동기화는 단순히 배타적 실행뿐 아니라 스레드 사이의 안정적인 통신에도 반드시 필요하다.
동기화를 하지 않는 경우#
- 공유중인 가변 데이터를 원자적으로 읽고 쓸 때 동기화에 실패하면 심각한 결과로 이어지게 된다.
public class StopThread {
private static boolean stopRequested;
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(() -> {
int i = 0;
while(!stopRequested) {
i++;
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}
- 이 프로그램은 아타깝게도 1초 후에도 종료하지 않는다.
- 메인 스레드가 1초 후 stopRequested를 true로 설정하게 될 것 같지만 실상은 그렇지 않다.
- 이유는 동기화하지 않았기 때문인데, 동기화를 안하면 메인 스레드가 수정한 값을 백그라운드 스레드가 언제보게 될 지 보증할 수 없다.
- 동기화가 없는 코드에서 JVM은 다음과 같이 최적화를 수행한다.
//원래 코드
while(!stopRequested) {
i++;
}
// 최적화한 코드
if(!stopRequested) {
while(true) {
i++;
}
}
- 이를 JVM의 호이스팅 기법이라 부른다.
동기화를 하는 경우#
public class StopThread {
private static boolean stopRequested;
private static synchronized void requestStop() {
stopRequested = true;
}
private static synchronized boolean stopRequested() {
return stopRequested;
}
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(() -> {
int i = 0;
while(!stopRequested()) {
i++;
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
requestStop();
}
}
- requestStop과 stopRequested을 동기화한 것은, 쓰기와 읽기 모두 동기화 되어야 동작을 보장하기 때문이다.
- 위와 같은 경우 매번 동기화하는 비용이 크진 않겠지만 속도가 더 빠른 volatile로 선언하면 동기화를 생략할 수 있다고 한다.
public class StopThread {
private static volatile boolean stopRequested;
public static void main(String[] args) throws InterruptedException {
Thread backgroundThread = new Thread(() -> {
int i = 0;
while(!stopRequested) {
i++;
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}
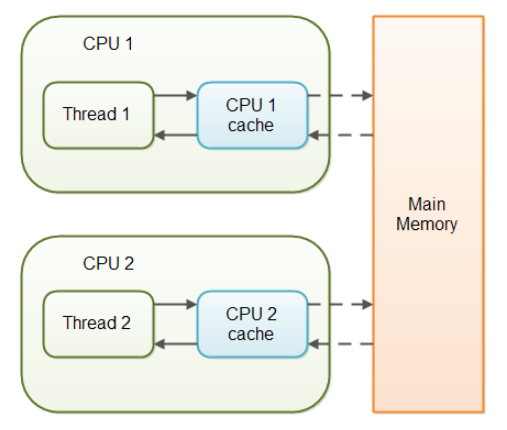
- 자바 volatile은 변수를 읽어올 때 CPU 캐시가 아닌, 매 번 메인 메모리에서 가져온다.
- 즉, read/write 모두 메인 메모리에서 수행한다는 의미이다.
- volatile은 배타적 수행하는 것과 관계 없이, 항상 최근에 기록된 값을 읽어오기 때문에 위 프로그램이 1초 뒤에 종료되는 것이다. (쓰레드나 동기화와는 무관)
volatile 사용시 주의할 점#
private static volatile int nextSerialNumber = 0;
public static int generateSerialNumber() {
return nextSerialNumber++;
}
- 위 코드는 얼핏 봐서는 크게 문제가 없을 것으로 보인다.
- 그러나 nextSerialNumber 변수가 volatile이고, nextSerialNumber++로 인해 문제가 발생한다.
- ++ 연산자는 nextSerialNumber = nextSerialNumber + 1과 같은 의미를 갖다.
- 멀티 스레드 환경에서 첫 번째 스레드가 값을 읽고, 1을 증가한 새로운 값을 저장할 때 두 번째 스레드가 이 사이를 비집고 들어와서 값을 읽어가면 첫 번째 스레드와 동일한 값을 돌려받게 된다.
- 이러한 오류를 safety failure라고 부른다.
private static volatile int nextSerialNumber = 0;
public static synchronized int generateSerialNumber() {
return nextSerialNumber++;
}
- 문제를 해결하는 가장 쉬운 방법은 synchronized 키워드를 붙이는 것이다.
- 이 메서드를 더 견고하게 사용하려면 int 타입 대신 long을 사용하는 편이 더 낫다.
java.util.concurrent.atomic#
- 자바 표준 라이브러리에는 concurrent 패키지가 존재한다.
- 이 패키지에는 여러 동시성 보장 클래스들이 존재하는데, 특히 atomic 패키지의 AtomicLong이 대표적인 예이다.
private static final AtomicLong nextSerialNum = new AtomicLong();
public static long generateSerialNumber() {
return nextSerialNum.getAndIncrement();
}
- 이 패키지는 원자성을 지원해준다.
요약#
- 동시성 문제를 피하는 가장 좋은 방법은 가변 데이터를 공유하지 않는 것이다.
- 가변 데이터는 단일 스레드에서만 쓰도록 하자.
- 불변 객체를 사용하면 이러한 문제를 만나지 않을 수 있다.
- 만약 여러 스레드가 가변 데이터를 공유한다면, 그 데이터를 읽고 쓰는 동작은 반드시 동기화해야 한다.
- 배타적 실행 (한번에 한스레드) 동작이 필요없고, 스레드 간 최신데이터만 읽는 거로도 충분하면 가변 변수에 volatile 키워드만으로도 동기화가 가능하다.
과도한 동기화는 피하라#
item 79
- 과도환 동기화는 성능을 떨어뜨리고, 교착상태에 빠뜨릴 수 있다.
- 응답 불가와 safety failure를 피하려면 동기화 메서드나 동기화 블록 안에서는 제어를 절대로 클라이언트에 양도해서는 안된다.
- 예를 들어, 동기화된 영역 안에서는 재정의할 수 있는 메서드를 호출해서는 안되며, 클라이언트가 넘겨준 함수 객체를 호출해서도 안된다.
- 동기화된 영역을 포함한 클래스 관점에서는 이 메서드들은 Alien Method이기 때문에 바깥 세상의 메서드들을 동기화 영역 내부에서 사용하는 것은 금지다.
public class ObservableSet<E> extends ForwardingSet<E> {
public ObservableSet(Set<E> set) {
super(set);
}
private final List<SetObserver<E>> observers = new ArrayList<>();
public void addObserver(SetObserver<E> observer) {
synchronized (observers) {
observers.add(observer);
}
}
public boolean removeObserver(SetObserver<E> observer) {
synchronized (observers) {
return observers.remove(observer);
}
}
private void notifyElementAdded(E element) {
synchronized (observers) {
for(SetObserver<E> observer : observers) {
observer.added(this, element);
}
}
}
@Override
public boolean add(E element) {
boolean added = super.add(element);
if(added) {
notifyElementAdded(element);
}
return added;
}
@Override
public boolean addAll(Collection<? extends E> c) {
boolean result = false;
for (E element : c) {
result |= add(element);
}
return result;
}
}
- 디자인패턴 중의 하나인, 옵저버 패턴이다.
- addObserver와 removeObserver 메서드를 호출해 구독을 신청하거나 해지한다.
- 두 경우 다음 콜백 인터페이스를 메서드에 전달한다.
@FunctionalInterface
public interface SetObserver<E> {
void added(ObservableSet<E> set, E element);
}
- 이 인터페이스는 서로 다른 두 타입의 인자를 받아 소모하는 함수형 인터페이스 BiConsumer<ObservableSet<E>, E>와 완벽히 동일하다.
- 그럼에도 커스텀 함수형 인터페이스를 정의한 이유는 이름이 더 직관적이고 추후에 확장할 수 있기 때문이다.
- ObservableSet을 사용하는 것이 어떤 문제를 내포하고 있는지 다음을 봐보자.
외계인 메소드의 사용#
public static void main(String[] args) {
ObservableSet<Integer> set = new ObservableSet<>(new HashSet<>());
set.addObserver(new SetObserver<>() {
public void added(ObservableSet<Integer> s, Integer e) {
System.out.println(e);
if(e == 23) {
s.removeObserver(this);
}
}
});
for(int i = 0; i < 100; i++) {
set.add(i);
}
}
- 평상시에는 집합에 추가된 정숫 값을 출력하다가, 그 값이 23이면 자신을 제거하는 코드이다.
- 여기서 람다가 아닌 익명 객체를 사용한 이유는, removeObserver 메소드에 자기 자신을 넘겨야하는데 람다에서는 자기 자신을 참조할 수 단이 없기 때문이다.
- 이 프로그램은 23까지 출력한 다음 ConcurrentModificationException을 발생시킨다.
- 관찰자의 added 메서드 호출이 일어난 시점이 notifyElementAdded가 관찰자들의 리스트를 순회하는 도중이기 때문이다.
- added 메서드가 removeObserver를 호출하고, remove 메소드를 호출한다.
- 리스트에서 원소를 제거하려는데, 마침 지금은 이 리스트를 순회하는 중이다.
- notifyElementAdded 메서드에서 수행하는 순회는 동기화 블록 안에 있으므로, 동시 수정이 일어나지 않도록 보장하는 것은 맞지만, 정작 자신이 콜백을 거쳐 되돌아와 수정하는 것까지는 막지 못한다.
외계인 메서드의 데드락#
set.addObserver(new SetObserver<>() {
public void added(ObservableSet<Integer> s, Integer e) {
System.out.println(e);
if(e == 23) {
ExecutorService exec = Executors.newSingleThreadExecutor();
try {
exec.submit(() -> s.removeObserver(this)).get();
} catch(ExecutionException | InterruptedException ex) {
throw new AssertionError(ex);
} finally {
exec.shutdown();
}
}
}
});
- 이 프로그램은 에러는 나지 않지만, 교착 상태에 빠진다.
- 백그라운드 스레드가 s.removeObserver를 호출하면 관찰자를 잠그려고 시도하는데, 락을 얻을 수 없다.
- 왜냐하면 메인 스레드가 이미 락을 쥐고 있기 때문이다.
- 그와 동시에 메인 스레드는 백그라운드 스레드가 관찰자를 제거하기만을 기다리고 있다.
- 동기화된 영역 안에서 외계인 메소드를 호출하다 보니 이런 현상이 발생하는 것이다.
교착 상태의 해결 방법#
- 자바의 락은 재진입(reentrant)를 허용하므로 교착상태에 빠지지는 않는다.
- 재진입 가능 락은 객체 지향 멀티 스레드 프로그램을 쉽게 구현하게 해준다.
- 하지만 교착 상태가 될 상황을 safety failure로 변모시킬 수 있다.
- 이 경우 외계인 메소드를 바깥쪽으로 옮기면 된다.
private void notifyElementAdded(E element) {
List<SetObserver<E>> snapshot = null;
synchronized(observers) {
snapshot = new ArrayList<>(observers);
}
for (SetObserver<E> observer : snapshot) {
observer.added(this, element);
}
}
CopyOnWriteArrayList#
- 외계인 메소드 호출을 동기화 블록 바깥으로 옮기는 것 보다 더 좋은 방법이 있다.
- 자바의 동시성 컬렉션 라이브러리의 CopyOnWriteArrayList를 사용하는 것이다.
- 내용은 내부를 변경하는 작업은 항상 깨끗한 복사본을 만들어 수행하도록 구현되었다.
- 내부의 배열은 절대 수정되지 않으니 순회할 때 락이 필요 없어 매우 빠르다.
private final List<SetObserser<E>> observers = new CopyOnWriteArrayList<>();
public void addObserver(SetObserver<E> observer) {
observers.add(observer);
}
public boolean removeObserver(SetObserver<E> observer) {
return observers.remove(observer);
}
public void notifyElementAdded(E element) {
for (SetObserver<E> observer : observers) {
observers.added(this, element);
}
}
- 다음과 같이 observers를 CopyOnWriteArrayList로 선언하고, 옵저버를 등록시키면 동기화 키워드 없이도 동시성을 보장해줄 수 있다.
- 동기화 영역 안에서 외계인 메서드를 호출하는 것은, 외계인 메서드가 얼마나 오래 실행될지 알 수 없으므로 다른 스레드는 보호된 자원을 쓰지도 못하고 무한정 대기해야만 한다.
동기화의 진실#
- 기본 규칙은 동기화 영역 안에서 가능한 한 일을 적게 수행하는 것이다.
- 멀티코어가 일반화된 오늘날, 과도한 동기화가 초래하는 진짜 비용은 락을 얻는데 드는 CPU 시간이 아니다.
- 바로 경쟁하느라 낭비하는 시간 (Race Condition), 즉 병렬로 실행할 기회를 잃고 모든 코어가 메모리를 일관되게 보기 위한 지연시간이 진짜 비용이다.
가변 클래스의 작성할 때 두 가지 선택지#
- 1번 방법: 동기화를 전혀 하지 않고 클래스를 동시에 사용해야하는 클래스라면 외부에서 알아서 동기화하게 하자.
- 2번 방법: 동기화를 내부에서 수행해 스레드 안전한 클래스로 만들자. 단 이 방법은 클라이언트가 외부에서 객체 전체에 락을 거는 것보다 동시성을 월등히 개선할 수 있을 때만 사용하자.
요약#
- 교착 상태와 데이터 훼손을 피하려면 동기화 영역 안에서 외계인 메소드를 절대 호출하지는 말자.
- 동기화 영역 안에서의 작업은 최소한으로 줄이자.
- 가변 클래스를 설계할 때는 스스로 동기화해야 할지 고민하자.
스레드보다는 실행자, 태스크, 스트림을 애용하라#
item 80
- java.util.concurrent 패키지에서 실행자 프레임워크(Executor Framework)라고 부르는 인터페이스 기반의 유연한 테스트 실행 프레임워크가 생겼다.
- 다음과 같이 사용할 수 있다.
ExecutorService exec = Executors.newSingleThreadExecutor();
exec.execute(runnable); // 실행자에 실행할 테스크를 넘기는 방법
exec.shutdown(); // 실행자 서비스 종료
- 쓰레드를 직접 다루기 보다는 실행자 프레임워크를 사용하여 작업 단위와 실행 메커니즘을 분리하도록 하자.
- 작업 단위를 나타내는 추상 개념은 Task이다.
- 태스크에는 두 가지가 있는데, 하나는 Runnable이오, 그 사촌은 Callable이다. (둘의 차이는 Callable은 값을 반환하고 임의의 예외를 던질 수 있다.)
- 이 태스크를 수행하는 일반적인 메커니즘이 바로 실행자 서비스이다.
- 컬렉션 프레임워크가 데이터 모음을 담당하듯이, 실행자 프레임워크가 작업 수행을 담당해주게 된다.
실행자 프레임워크의 진화#
- 자바 7이 되면서 실행자 프레임워크는 포크-조인 태스크를 지원하도록 확장되었다.
- 포크조인 테스크의 인스턴스는 작은 하위 태스크로 나뉠 수 있다.
- ForkJoinPool을 구성하는 쓰레드들이 이 태스크들을 처리하며 일을 먼저 끝낸 쓰레드가 다른 쓰레드의 남은 태스크를 가져와 처리할 수 있다.
- 이렇게 모든 쓰레드들이 바쁘게 움직이며 CPU를 최대한 활용하여 높은 처리량과 낮은 지연시간을 달성한다.
- 이러한 포크-조인 태스크를 직접 작성하고 튜닝하기란 어렵지만, 포크-조인 풀을 이용해 만든 병렬 스트림을 사용하면 적은 노력으로 이점을 얻을 수 있다. (물론 포크-조인에 적합한 작업이야한다.)
wait와 notify보다는 동시성 유틸리티를 애용하라#
item 81
- wait, notify를 올바르게 사용하는 것은 까다로우니 고수준 동시성 유틸리티를 사용하자.
- java.util.concurrent의 고수준 유틸리티는 크게 세 범주로 나뉜다.
- 실행자 프레임워크, 동시성 컬렉션, 동기화 장치이다.
- 동시성 컬렉션은 List, Queue, Map과 같은 표준 컬렉션 인터페이스에 동시성을 가미해 구현한 고성능 컬렉션이다.
- 동시성 컬렉션에서는 높은 동시성을 달성하기 위해 동기화를 각자의 내부에서 수행하며, 동시성을 무력화하는 것은 불가능하고 외부에서 락을 추가로 사용하면 오히려 성능이 더 떨어진다.
요약#
- wait, notify는 이제 과거의 유물이다. like 어셈블리
- wait, notify보다는 동시성 유틸리티를 사용해 제어하도록 하자.
스레드 안정성 수준을 문서화하라#
item 82
- 일반적으로 API 문서에서 synchronized 키워드까지는 명시하지는 않는다.
- 그러나 클라이언트가 멀테스레드 환경에서도 API를 안전하게 사용할 수 있게 스레드 안정성 수준을 명확하게 명시해두어야한다.
- 다음 나열은 스레드가 안전한 순서대로 나열한 스레드 안전성에 대한 문구를 정리한 것이다.
- Immutable(불변), unconditionally thread-safe(무조건적 스레드 안전), conditionally thread-safe(조건적 스레드 안전), not thread-safe(스레드 안전하지 않음), thread-hostile (스레드 적대적) 순이다.
- 보통 일반적으로 클래스의 스레드 안정성 수준은 클래스 문서화 주석에 포함하지만, 독특한 메서드라면 해당 메서드 주석으로 남겨놓자.
- 무조건적 스레드 안전 클래스에서는 synchronized 메서드 보다는 비공개 락 객체를 사용하자. 왜냐하면 상속받은 하위 클래스나 클라이언트가 동기화 메커니즘을 깨뜨릴 수 있기 때문이다.
요약#
- 모든 클래스는 자신의 스레드 안정성 정보를 명확히 문서화해야 한다.
- 무조건적 스레드 안전 클래스를 작성할 때는 synchonized 메서드가 아닌 비공개 락 객체를 사용하자.
지연 초기화는 신중히 사용하라#
item 83
- 지연 초기화는 양날의 검이다.클래스 혹은 인스턴스 생성 시의 초기화 비용은 줄지만, 그 대신 지연 초기화하는 필드에 접근하는 비용이 커진다.
- 멀티스레드 환경에서 지연 초기화는 더더욱 까다롭다.
- 지연 초기화하는 필드가 둘 이상의 스레드가 공유한다면 어떻게든 동기화를 해야한다.
- 대부분의 상황에서 일반적인 초기화가 지연 초기화보다 낫다.
- 성능 때문에 정적 필드를 지연 초기화해야한다면, 지연 초기화 홀더 클래스 관용구를 사용해보자.
private static class FieldHolder {
static final FieldType field = computeFieldValue();
}
private static FieldType getField() {
return FieldHolder.field;
}
- getField가 처음 호출되는 순간 FieldHolder.field가 처음 읽히면서 비로소 FieldHolder가 초기화된다.
요약#
- 대부분의 필드는 지연시키기보다는 곧바로 초기화하는 편이 더 낫다.
- 성능 때문에, 혹은 위험한 초기화 순환을 막기 위해 지연 초기화를 써야한다면 올바른 지연 초기화 기법을 사용하자.
- JPA에서는 지연 로딩을 사용 시 프록시 객체를 사용하여 특정 필드의 초기화를 늦추는 기법을 사용하고 있다.
프로그램의 동작을 스레드 스케줄러에 기대지 말라#
item 84
- 정확성이나 성능이 스레드 스케쥴러에 따라 달라지는 프로그램은 다른 플랫폼에 이식하기 어렵다.
- 견고하고 빠른 프로그램을 작성하는 좋은 방법은 실행 가능한 스레드의 평균적인 수를 프로세서 수 보다 지나치게 많아지지 않도록 하는 것이다.
- 실행 가능한 스레드 수를 적게 유지하는 주요 기법은 각 스레드가 무언가 유용한 작업을 완료한 후에는 다음 일거리가 생길 때까지 대기하도록 하는 것이다.
- 스레드는 당장 처리해야할 작업이 없다면 실행되서는 안된다.
- 실행자 프레임워크의 경우 스레드 풀 크기를 적절히 설정하고 작업은 짧게 유지하게 하면 된다.
- 스레드는 절대 바쁜 대기(busy wating) 상태로 두어선 안된다.
- 공유 객체의 상태가 바뀔 떄까지 쉬지않고 검사해서는 안된다는 뜻이다.
- 특정 스레드가 다른 스레드 보다 CPU 시간을 충분히 얻지 못해서 간신히 돌아가는 프로그램에서 Thread.yield를 사용해 문제를 고쳐보려는 유혹을 떨쳐내자.
- 그것은 그 JVM에서만 유효할 뿐 다른 JVM에서는 어떻게 될지 모른다. 심지어 Thread.yield는 테스트할 수단도 없다.
요약#
- 프로그램의 동작을 스레드 스케쥴러에 기대지 말자.
- Thread.yield와 스레드 우선순위에 의존해서는 안된다.
- 이 기능들은 스레드 스케쥴러에 제공하는 힌트일 뿐이다.
- 스레드 우선순위는 이미 잘 동작하는 프로그램의 서비스 품질을 높이기 위해 드물게 쓰일 수 있지만, 간신히 동작하는 프로그램을 고치는 용도로써 사용해서는 안된다.
'자바' 카테고리의 다른 글
| [스레드 동기화] 수업에했던 외운 스레도 동기화 (0) | 2023.04.03 |
|---|---|
| [스레드 동기화] 좋은 스레드 동기화 예제 (0) | 2023.04.03 |
| 스트림 외울거 (1) | 2023.03.30 |
| [객체배열] 오름차순 (0) | 2023.03.24 |
| [정규식] _포함 안포함 비교 (1) | 2023.03.24 |





댓글 영역